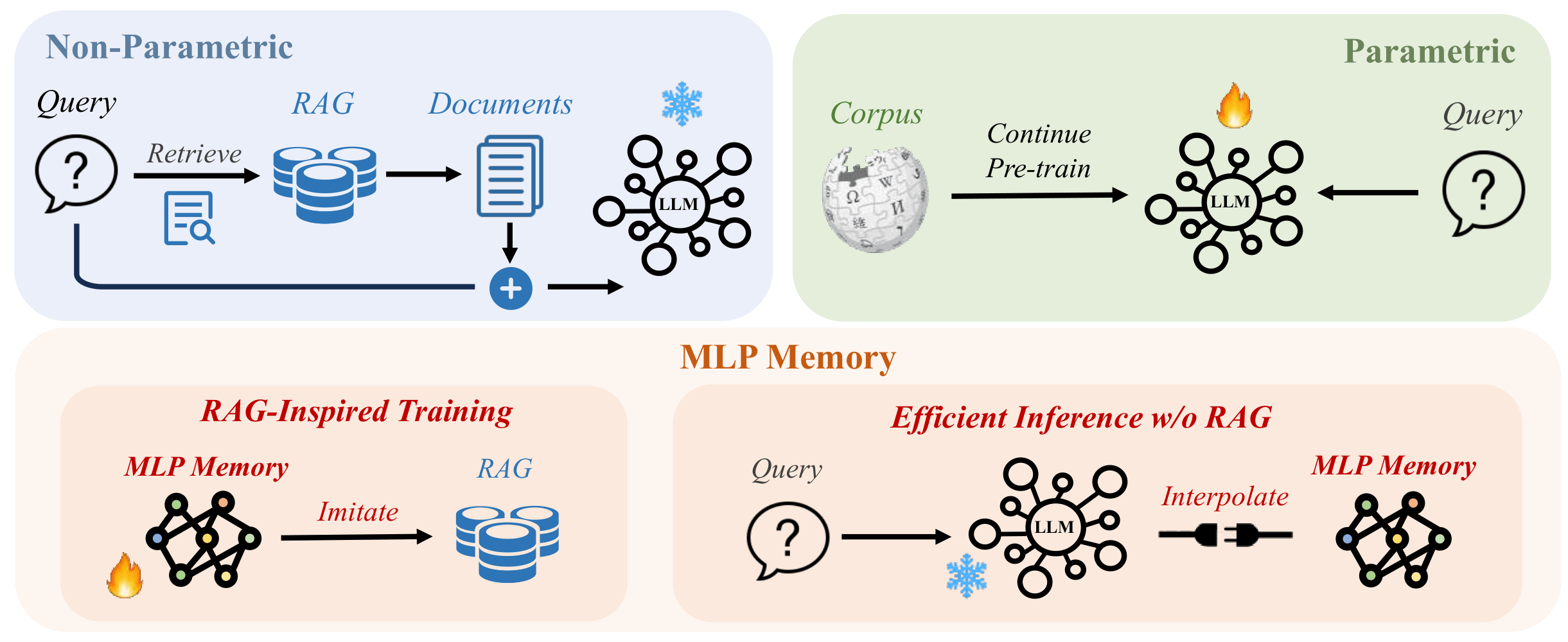
We present MLP Memory, a lightweight parametric module that pretrains an MLP to imitate a kNN retriever’s behavior on the entire pretraining dataset. This creates a differentiable memory component that internalizes retrieval patterns without explicit document access, achieving 17.5% and 24.1% scaling gains on WikiText-103 and Web datasets, respectively.
@inproceedings{wei2026mlpmemory,title={MLP Memory: A Retriever-Pretrained Memory for Large Language Models},author={Wei, Rubin and Cao, Jiaqi and Wang, Jiarui and Kai, Jushi and Guo, Qipeng and Zhou, Bowen and Lin, Zhouhan},booktitle={International Conference on Learning Representations},year={2026},}
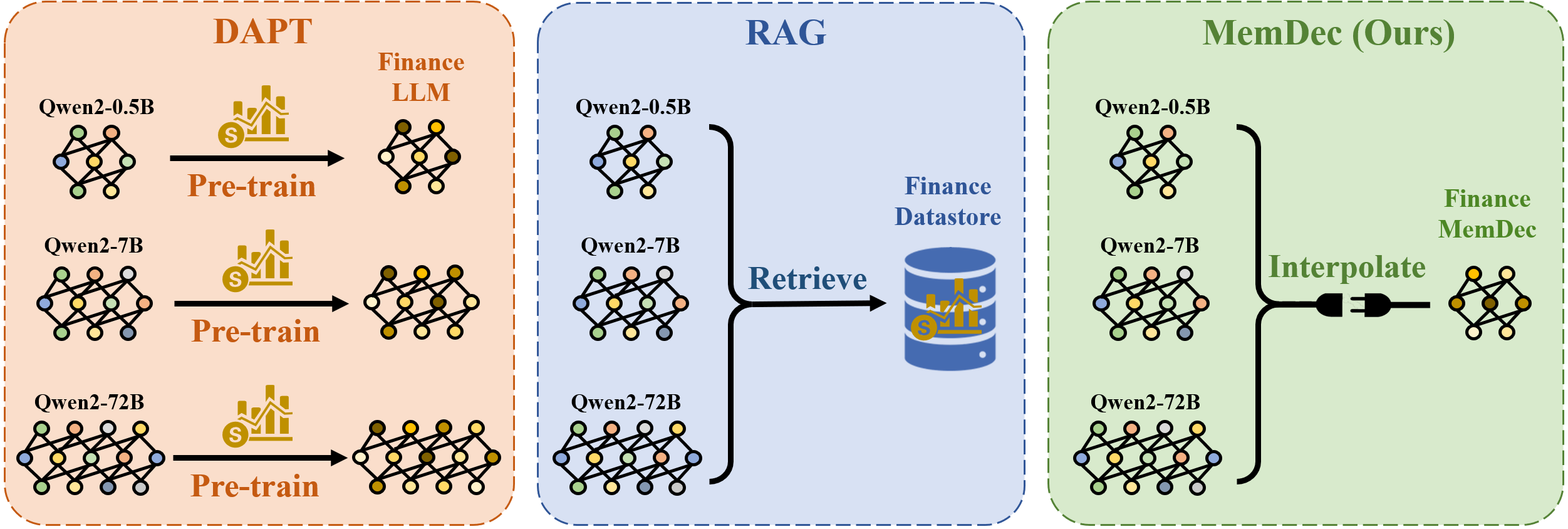
Large Language Models (LLMs) excel at general language tasks but struggle with domain adaptation. Domain Adaptive Pretraining (DAPT) is costly and suffers from catastrophic forgetting, while Retrieval-Augmented Generation (RAG) introduces substantial inference latency. We propose Memory Decoder, a pretrained, plug-and-play memory module that enables efficient domain adaptation without modifying the original model’s parameters.
@inproceedings{cao2025memorydecoder,title={Memory Decoder: A Pretrained, Plug-and-Play Memory for Large Language Models},author={Cao, Jiaqi and Wang, Jiarui and Wei, Rubin and Guo, Qipeng and Chen, Kai and Zhou, Bowen and Lin, Zhouhan},booktitle={Advances in Neural Information Processing Systems},year={2025},}